

Introduction
Building a usage based metering and pricing system entails addressing a tremendous amount of technical challenges. Feel free to skim through the previous blog detailing these complexities. In order to tackle the technical challenges, we defined key tenets and ensured that our tech choices upheld them. We have also devised basic guidelines to be followed to achieve each tenet.
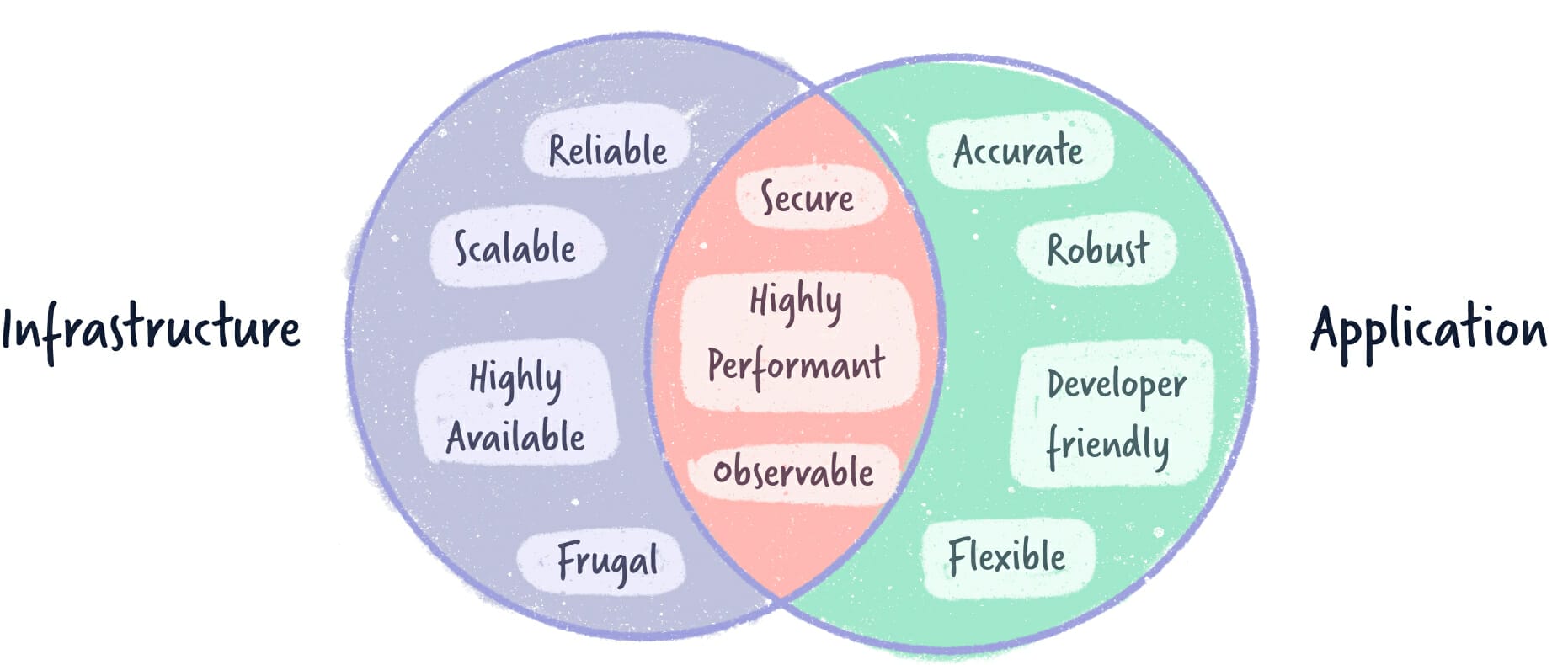
Infrastructure
1. Highly Available
We would be collecting the events from our customers as and when they occur to provide real-time metrics, our system should be built with a minimum of 4-9s of availability.
Guidelines:
- Use horizontally scalable services
- Set up across at least 2 availability zones
- Implement redundancy for components to avoid single point of failure
2. Reliable
Once the events are received, we want to act as the source of truth for it. The same applies to the usage and revenue metrics computed from the raw events.
Guidelines:
- Configure periodic backups
- Provide mechanisms to detect outages and trigger failover
3. Scalable
As the usage and count of our customers grow, our components should scale up to handle the requests. The process of scaling up should be very simple as well.
Guidelines:
- Setup the infrastructure via code
- Use configuration management tools to set up the components
4. Frugal
When we scale up, the cost implication should be minimal. The savings from here can be transferred back to our customers.
Guidelines:
- Burstable instance types can be used to avoid paying peak charges 24x7
- Choose services that perform well with low resource utilization
Application
1. Accurate
We want to act as the source of truth for the computed usage and revenue metrics as well, so there is no margin for error. Only valid events should be filtered and processed, as corrupted data points lead to invalid bills.
Guidelines:
- Use strongly typed languages and define solid contracts for all modules
- Formulate stringent test cases and automate them with a test suite
2. Developer Friendly
We optimize for the speed and ease of integration - our goal is to become as easy as it is to integrate with as an APM tool and become part of the observability stack itself at the client end.
When making a “Build vs. Buy” decision, the ease of integration with the external system will persuade the decision to “Buy”.
Guidelines:
- Provide native integrations with tools and frameworks that developers already use
- Accept unique identifiers from the payload and provide durability on it, thereby removing the need for state & identifier management at their end
- Track invalid request payloads separately as “unprocessed” which will help the developers in debugging
3. Robust
The events should be processed once and only once. This ensures that there is no duplicate billing or loss in revenue.
Guidelines:
- Ensure idempotency in the event processing actions
- Track the state of each event and build solid-state management workflows
4. Flexible
Customization is the most critical feature for any good metering & pricing platform. Experimentation will warrant a variety of computation strategies.
Guidelines:
- Design for the long term and implement for the short term
- All functions should have placeholders to support future use cases
Also Read: Mastering Togai Through Public Sandbox: A Comprehensive Guide for Customers
Common to both
1. Highly Performant
As we are consuming the events as and when they occur, the volume of requests will be very high. There should be minimal latency at our end so that the cost of pushing events to us is not high for our customers.
Guidelines:
- Stress test various options before using the services
- Use appropriate instance types for the components based on their behaviour
2. Secure
As a multi-tenant system, we should ensure that the access to our customer’s data is restricted to only them. The services and infra components should also be orchestrated with security as a factor.
Guidelines:
- Crosscheck the tools and services for CVE in various vulnerability databases. Also, check for open issues in the projects
- Architect the cloud network such that only required ports and IPs are exposed on the relevant servers
- On every request, ensure that the user is authenticated & authorized to access the requested data
3. Observable
In order to understand the consumption, durability & performance of the component, the system and process metrics along with service & app logs should be tracked and monitored.
Guidelines:
- Use infra-monitoring tools to track the services and alert on anomaly
- Use APM tools to monitor the application performance and errors
- Use log aggregation system to unify and query application and infra-service logs
What’s Next
One of the key traits that we acquired from our previous venture, Hypto is the ability to make trade-offs. This is crucial to build a product at a very high momentum. Stay tuned to learn more about the trade-offs that we have taken, our tech choices, and the components that we have built for our UBP product. Feel free to DM me on LinkedIn or Twitter to share your experiences in implementing these tenets in your system.







