

Building a billing software may seem trivial at the onset but the devil lies in the details. Our CTO wrote a fantastic blog post on why building a billing software is challenging. But this complexity and challenge reach multi-fold when building a usage-based billing platform as the amount of data to be processed by a usage-based billing platform is huge. So choosing the right technology is crucial in determining the success of Togai.
Before we jump on to what powers Togai, a quick look on the software tenets (another great blog from our CTO) will help to understand the rationality behind the choices we took in building Togai.
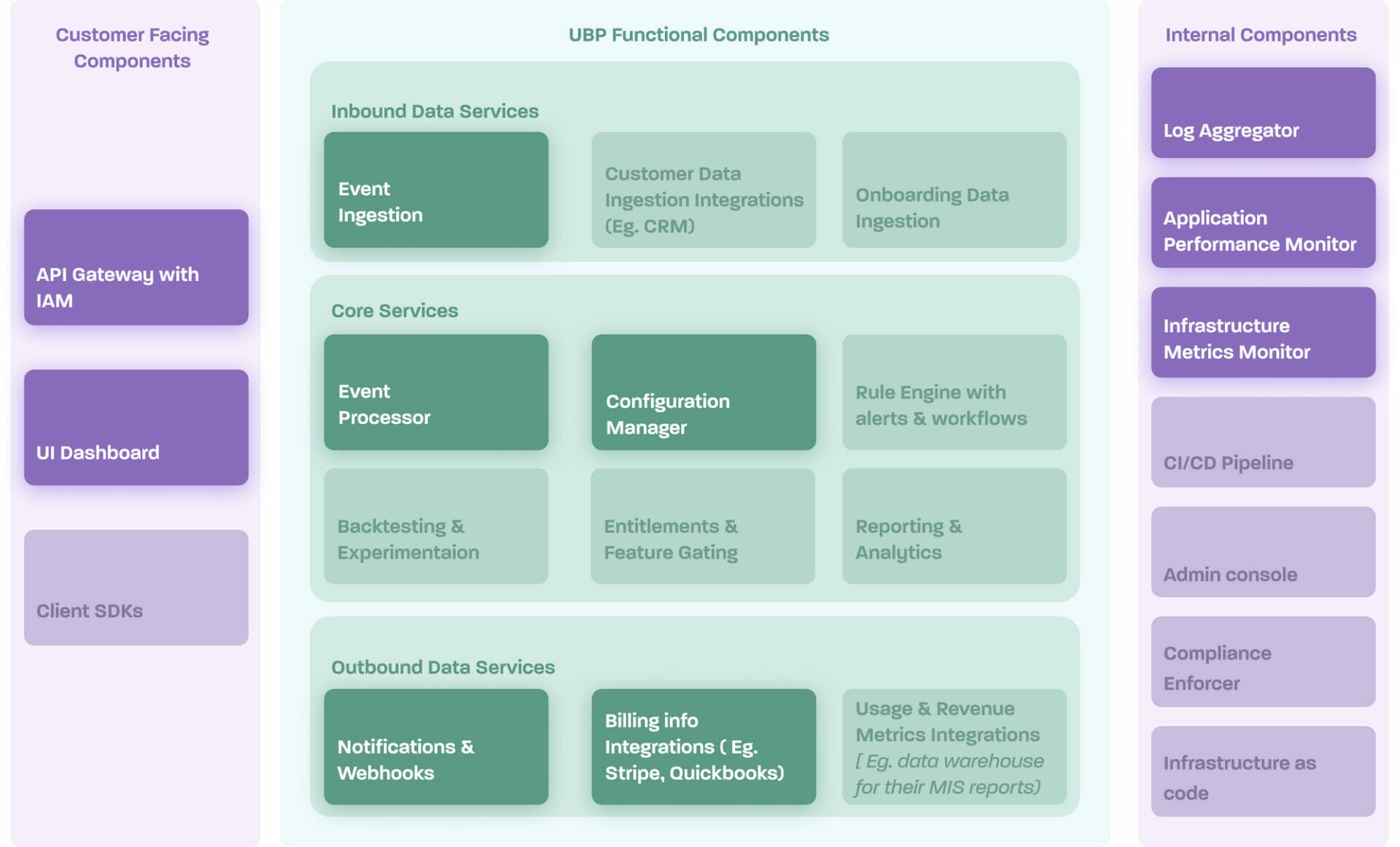
Togai backend architecture
Togai is modelled as a microservices-based architecture from the first version. Monoliths would have helped us to build quicker but since Togai promises high throughput(nearly unlimited) from Day 1 for our customers, we decided to go with micro-services-based architecture so that we have the flexibility to choose and scale critical components in the event processing pipeline.
Tech choices
Language & Framework (Kotlin, Ktor, Javascript, Loopback, Vue3)
To build Togai, we wanted a strongly typed language with type checking at compile time so that any errors could be detected earlier in the development lifecycle. Also, we strongly believe in the FOSS model. So majority of Togai backend was built with Kotlin. Kotlin was chosen because it is a fantastic expressive language, helped us to achieve more with less code. Kotlin has a superior type system when compared to Java and with powerful features like coroutines, null safety, and first-class interoperability support with Java, it was fun writing software in Kotlin. Kotlin is in the JVM ecosystem, so we were able to leverage amazing third-party open-source libraries in the JVM eco-system while building Togai. A big shout-out to these amazing libraries that helped in building Togai.
- Ktor - Ktor is a HTTP web framework written ground-up in Kotlin. Ktor’s simple constructs helped us to build components faster. Also because of the native co-routine support, we are able to build systems that handles large scale throughput.
- JooQ - Message from the website says it all - "jOOQ generates Java code from your database and lets you build type-safe SQL queries through its fluent API”. It's a nice library that helped us to stay in the strongly-type realm.
- Flyway - Flyway helped us to manage DB migrations.
- HikariCP - A lightweight DB connection pooling library. Helped to optimize connections between DB and application servers.
- Hoplite - A Kotlin native configuration management library. Helped to internally manage configurations specific to environments. Word of caution - This library is not backed by any organisation but maintained by an amazing individual - Sam - who was very prompt & accessible in responding to our queries.
- Logback - An SLF4J compatible logging framework.
- Koin - A dependency injection framework written ground-up with Kotlin.
- JsonLogic - A specification helped us to represent logic in JSON. This is also maintained by an individual and not backed by any organization. Overall JSONLogic is a fantastic idea which deserves support from the community. Kudos to the maintainer - Jeremy Wadhams.
- Cohort - Health check library is natively written in Kotlin. This library is also managed by - Sam.
- JUnit5 - A de-facto testing framework for JVM based apps.
- TestContainers - A library helped us to mock databases for running tests.
While building Togai with Kotlin, we became a fan of Kotlin’s cooperative multitasking construct - “Coroutines”. In our load tests, with just a t4g.small instance (a 2 vCPUs and 4 GB RAM machine), we are able to achieve 60 TPS (transactions per second) with a baseline 20% CPU. This load was handled with request latency within our SLA of 1 second. It was a pleasant surprise to know the power of multi-tasking efficiency of coroutines. Who in the world will not like this sort of performance where more than 100M requests per month are handled by just spending less than 30$ rent on a box. Yeah, Kotlin and Ktor definitely turned out as a great choice for us in building Togai.
But Togai backend was not entirely built with Kotlin. We also have a NodeJS-based service to ingest events from clients. We choose NodeJS for ingestion component because of the async IO. Since Togai ingestion is all about IO where clients send usage events and the events are validated and pushed to a queue, we choose NodeJS.
Choosing multiple languages created an interoperability problem. So we used OpenAPI. OpenAPI is a programming language agnostic standard to build HTTP-based RESTful APIs. With defined API spec, developers are free to write the backend in any language and clients are free to integrate Togai APIs using any language they like. Also, OpenAPI tech is supported by a strong community with amazing tools, this helped us offload mundane tasks like input invalidations, GUI explorers, server/client code generators, and test automation to those open-source tools which helped to speed up our development.
Frontend (Vue3)
Togai front-end is completely built with Vue3 JS framework. We will have a separate blog post detailing the front-end architecture and trade-offs we took during implementation.
Database (Postgres, TimeseriesDB)
We love Postgres. It is one of the most advanced databases available today with strong community support. It has rich feature sets like transactions, partitions, extensions, views, indices with different types, data types, constraints supports and lot more. We used Postgres extensively in Togai.
But like any software, Postgres is also not perfect. There are few painful problems in Postgres like replication configuration, fail-over management, garbage collection (vaccum), version upgrades etc but overall it's a well engineered product with rich features. In our company’s earlier avatar hypto.in, we processed millions of transactions worth billions of dollars with Postgres. So with the right tuning, we know that we can make Postgres powerful.
But in Togai, not all data is relational. Every time we get a usage event from our customers, it has a timestamp, we meter and calculate revenue for each event. So it is basically a timeseries data and all queries to the usage, revenue will be based on time ranges. We evaluated different timeseries storage solutions (like influxDB, Amazon timestream) to handle aggregations, downsampling etc. in the database layer. After detailed evaluation, concluded to use TimescaleDB because of two reasons 1) higher ingestion rate at scale 2) better query performance as compared to other timeseries solutions. Also TimescaleDB is an extension built on top of Postgres database so this gave us the confidence as we already knew Postgre’s capability.
Messaging (NATS)
Togai process events asynchronously. We needed a message queue solution to temporarily store all unprocessed events and keep it available for event processors to process. Managed message queue solution (like AWS SQS) was not preferred because of the cost at scale. So we evaluated Kafka & Nats for message queues. Unlike Kafka, Nats is solely built as a message queue keeping performance in mind at scale. Nats has smaller memory foot print compared to Kafka and simple to setup. In our load test, with just a t4g.small instance (a 2 vCPUs and 4 GB RAM machine), nats was able to support a throughput of over 5000 message per second with a CPU utilisation less than 5%. So spending less than 30$ a month, we are able to achieve a throughput of ~1B message processing.
Nats is the perfect candidate for Togai’s message solution. But there is a catch, we are new to NATS and messaging is critical for Togai. So to avoid any unknown unknowns, we designed a backup messaging solution with AWS SQS queue. Messages will be automatically forwarded to AWS SQS in case there is any failure in NATS ingestion. This backup idea helped us to build a highly available, scalable messaging system at a cheap price.
Deployment
Togai is deployed and hosted in the AWS cloud. We got generous credits from one of our VC backers, so didn't investigate on other options. For infrastructure we use terraform and chef for infrastructure config management. This helped to configure all infrastructure components (like NATS, Nginx, redis, postgres, and app servers) with code.
Local development env
Setting a local environment for Togai is complex as it requires many components to run. We sought the help of docker-compose to run on our local desktops. However, we are facing some performance issues as the docker compose takes a lot of time which is impacting our development velocity. Investigating other options will have a blog post when we find any techniques to either fine-tune our docker-compose build or if we find any other alternatives.
Testing
As a startup company we focus on speed. So we prefer to write local integration tests than pure unit tests. We have a detailed blog planned on why we chose this approach but in short, it helped to push more features with higher quality in less time. You can find the working example of local integration tests in our open-source identity & access management service(github repo).
For integration tests, Togai relies on postman’s automation tool (newman) to test our backend APIs.
Also Read: Engineering Tenets
Operations
Vector - For log collection, we use Vector to push application logs from the server to a central log store. We evaluated other collector agents (like Logstash, FluentD) and settled on “Vector” because of its less memory foot-print and high performance. Currently we store the aggregated logs in a central log store backed by AWS EBS.
Newrelic - We use this paid observability solution to monitor app servers, infrastructure & front-end synthetics.
Emails - We use emails to notify any alerts from newrelic. We are looking to update to pagerDuty or any other better notification systems for alerts.
Other logistics - Trello, GitHub & Slack
Summary
This blog post contains lot of opinionated choices. We are not claiming our choices are the best. Like every software, there are pros and cons in this list. We mainly choose these technologies and libraries based on 1) our design tenets, 2) technology familiarity and 3) development speed. Hope this post helps you in taking a better informed decision while choosing technology for your apps in future.







